
 Yahoo奇摩新聞
Yahoo奇摩新聞 
微軟vsGoogle:語言模型會不會壓倒搜尋引擎?
很明顯,二十年來幾乎停滯不前的搜尋領域即將迎來前所未有的拐點。
神譯局是36氪旗下編譯團隊,關注科技、商業、職場、生活等領域,重點介紹國外的新技術、新觀點、新風向。
編者按:ChatGPT 無疑是人工智慧領域近期最閃耀的一顆星。在背後投入重注與資源的微軟已經開始計畫用它來改進自家產品。甚至有小道消息稱微軟打算將 ChatGPT 嵌入到搜尋引擎 Bing 裡面,向佔據霸主地位二十多年的Google發起挑戰。那麼,微軟會成功嗎?在搜尋和人工智慧領域都有技術優勢的Google會做何打算?文章來自編譯。

泰坦之戰。來源:Midjourney
有傳言稱,微軟悄然啟動了一個有望在未來幾年影響到科技領域格局的項目。正如 The Verge 的 Tom Warren 所寫那樣,這家軟體巨頭“據報導打算推出一版利用 ChatGPT 的 Bing 。”果真如此的話,搜尋即將經歷一場革命,這是二十年來的頭一遭。
在 OpenAI 發佈 ChatGPT 過去了一個月之後,這個消息並不是很令人感到意外。ChatGPT 是一款強大的針對會話進行了最佳化的語言模型(LM),在我看來,這是目前全世界最好的聊天機器人了——儘管這個地位可能不會持續太久。
在 ChatGPT 於 2022 年 11 月 30 日發佈之後,人們很快意識到它的存在意味著 LM 有可能在短期內超越傳統搜尋引擎(SE)成為線上資訊檢索的主要手段。引申而言,這意味著Google在搜尋領域長達二十年的霸主地位也許正變得岌岌可危。
微軟(非官方的)公告重新點燃了 LM 與 SE 之爭,儘管沒有人確切知道這件事後續將如何展開,但大家在一件事上幾乎已經達成了共識;從某種程度來說,LM 和搜尋在未來很可能會成為一個更大整體不可分割的部分。
就像地心引力會將我們拉往地面一樣,技術也會自發地朝著一個方向流動(正如熱力學的規律一樣):讓我們的生活更加輕鬆。LM 更直觀,與它們的互動對我們來說很自然。SE 要麼改變要麼等死的結果似乎不可避免。
我知道,這種話聽起來就像那種典型的一般不可證偽的預測。值得慶幸的是,有些未知我們是可以解釋清楚的:比如 ChatGPT 會不會對Google構成真正威脅?微軟能掀翻Google嗎?這家搜尋巨頭能否做出充分反應?最終哪家公司會拔得頭籌?LM 會取代或削弱搜尋嗎?還是作為搜尋的補充?LM 會在哪些方面改進或削弱搜尋?這一切將如何發生,什麼時候會發生?
我們可以試著回答其中的一些問題,並在此過程中瞭解 LM 與 SE 未來將如何互動,微軟、Google以及 OpenAI 對這一切有何看法,還有就是我所認為的未來幾個月/幾年這出大戲會如何鋪開。
語言模型與搜尋引擎
ChatGPT 推出的那一天,Twitter 上有個叫 josh 的使用者馬上就說:“Google完蛋了。”其他人,比如 George Hotz 也同意這個說法——但並不是每個人都得出相同的結論。
Gary Marcus 教授用經驗證據反駁了 George Hotz 的觀點,Google的 François Chollet 也指出了類似的問題:“搜尋屬於搜尋問題,而不是生成問題。”

流形內插很適合生成式任務(如創作詩歌或圖像),但對搜尋不管用(如資訊獲取)。確實是可以用大型語言模型替代搜尋引擎,而且體驗會好很多(只要你對獲得的大多數資訊都是編造出來的不在意的話,或者不需要溯源的話......)
我同意 Marcus 和 Chollet 的觀點。LM 本身並不適合勝過 SE。不過,SE 可以得到顯著改進,以至於那些未整合基於 LM 的功能的 SE 會變得過時。
如果我們接受這個假設的話,那麼很容易就能看出,在 LM 與搜尋的結合方面,最有優勢的應該就是Google,而不是 OpenAI,或者微軟。這兩個領域單獨拎出來Google的全球領先地位都是無可撼動的。儘管 OpenAI 很受歡迎,但 GPT-3、ChatGPT 以及所有類似模型都是基於Google的技術,而Google的 SE 則佔據了 4/5 的市場份額。
如果說這家公司並沒有推出太多的人工智慧產品,正如 Stability 的 Emad Mostaque 所言,那是因為它的“體制惰性”。在研究的深度和廣度上,Google無疑是全球領先的人工智慧公司。
不過,就像很受歡迎的投資人 Balaji Srinivasan 所解釋的那樣,研究與生產是迥異的兩種野獸:如果以 LM 為基礎對自己的 SE 進行徹底重構的話,Google無法承擔相關的風險。多年來,這家公司一直在推出新的搜尋功能,但那些都是漸進式的變更,沒有一個能像微軟(以及 Perplexity、You 和 Neeva 等其他公司)似乎正在做的事情那樣具有革命性。
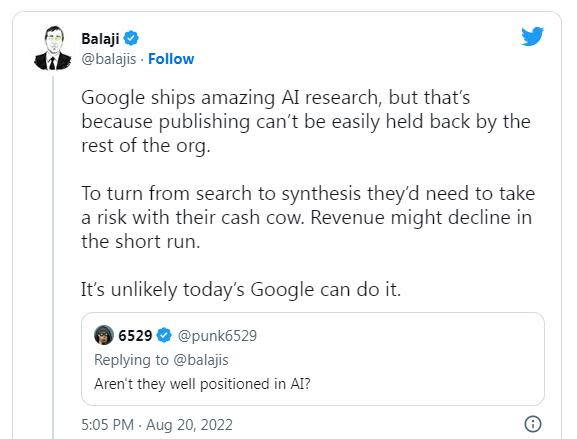
Google發表AI研究不會遇到內部阻力,但如果應用到商業的話,現有搜尋業務短期內會受到衝擊。
我對 LM 與 SE 的看法可以總結如下:“搜尋引擎的侷限性要大得多,但更有利於搜尋 web 這件事情……不過我並不認為[傳統]搜尋引擎能挺過 LM 的進攻。”這裡的關鍵詞——我在原文沒有標出來——是“傳統”。
SE 會繼續存在,但形態會非常不同,差別會大到你認不出來。LM 很可能就是原因。
(把 LM 整合進 SE 是不是好主意這裡我不會詳細討論。關於這一點,Gary Marcus 有一篇很棒的文章,《Is ChatGPT Really a “Code Red” for Google Search ?》,他說的我幾乎完全認同)
微軟 vs Google:劃時代的科技之戰
微軟對 OpenAI 投入了 10 億美元,以及他們獲得後者部分 AI 技術堆疊的獨家許可,是微軟對這一領域很感興趣的明確訊號。他們計畫將 DALL-E 和 ChatGPT 整合到自己的服務中也就不足為奇了。正如 Tom Warren 所寫的那樣,增強的 Bing SE 可以“挑戰Google的主導地位”。
當然,其想法不是用 LM 取代 SE,而是對搜尋進行補充。微軟的一位發言人告訴彭博社,“對使用者查詢採取對話式、上下文式的回覆可以提供超越連結的質量更高的答案,從而贏得搜尋使用者的青睞。”
與Google不一樣,微軟非常清楚 LM 不如 SE 那麼可靠。為了在與Google之戰中贏得潛在優勢,這家公司將被迫評估實現人們不能 100% 依賴的功能有何風險。微軟正在“權衡……聊天機器人的精準性,我們的初始版本可能只會針對一小部分使用者進行有限的測試。”聽起來是個合理的開始。
但是,如果有誰比微軟還要瞭解 LM 可以做什麼和不能做什麼的話,那非Google莫屬。早在 2021 年(這個時間要遠早於 ChatGPT 甚至成為一個想法種子的時間)的一篇論文中,Google的研究人員就探討了利用 LM 來“重新思考搜尋”的問題。
他們當時思考的是能不能這麼做,以及更重要的是,是否應該這樣做:
典型的資訊檢索系統 [也就是傳統 SE] 不直接回答資訊需求,而是提供(希望是權威的)答案的引用。……相比之下,預訓練的語言模型能夠直接生成可能對資訊需求做出響應的文字,但目前的水平屬於業餘愛好者而不是領域專家——這些模型對這個世界缺乏真正的理解,而且很容易會產生幻覺,至關重要的是,它們沒法通過參考受訓的語料庫中的支援檔案來證明自己的言論是正確的。
Google的最終結論是,使用類似於 ChatGPT 的系統來增強自己的搜尋引擎會帶來很高的“聲譽風險”。Google首席執行官桑達爾·皮查伊(Sundar Pichai)以及 AI 負責人 Jeff Dean 告訴 CNBC,“如果出問題的話,造成的成本會 [比 OpenAI ] 更高,因為人們必須相信他們從Google獲得的答案。”
2021 年 5 月,Google宣佈推出了 LaMDA (但並未發佈出去)。鑑於 LaMDA 與 ChatGPT 的可比性(如果不是像 Blake Lemoine 所聲稱的那樣比 ChatGPT 更好的話),我們有理由質疑為什麼Google沒有利用 LaMDA 來避免像 OpenAI 這樣的威脅。Balaji Srinivasan 預測這是因為該公司沒有足夠的“風險預算”,事實證明他是對的。
像Google這樣的大公司要為數十億使用者(而不是像 OpenAI 那樣幾百萬的規模)提供像Google搜尋這樣的高可靠性服務,不能僅僅因為一個東西似乎會成為未來,因為人人都為之瘋狂,就把一個不可信的、未經嚴格測試的新技術嵌入進來。
但Google的高管不是傻子。他們知道,由一家規模小得多、對風險的厭惡程度要低得多的公司所有的 ChatGPT 確實是個威脅——尤其是當像微軟這樣的直接競爭對手擁有其大量股份時更是如此。這就是為什麼他們宣佈 ChatGPT 為“紅色警戒”,正如《紐約時報》所報導的那樣:
……由於一種有望重塑甚至取代傳統搜尋引擎的新型聊天機器人技術的出現,Google重要的搜尋業務可能即將首次面臨嚴重威脅。一位Google高管將這些努力描述為決定了Google未來的成敗。……Google必須介入競爭,否則這個行業可能就會在沒有它的情況下繼續前進……
就目前的情況來看,Google面臨著微軟(在搜尋領域是一個強大的直接競爭對手)和 OpenAI(後者擁有極具競爭力的人工智慧技術,儘管預算要緊很多)的威脅。與此同時,對於 LM 因為內在的不可靠性會引起的聲譽風險,以及風險厭惡程度較低的初創公司所構成的明顯威脅,Google必須做出再三權衡。
正如皮查伊所說的那樣,Google“既要大膽,又必須負責任”,必須找到折衷方案。Dean 則總結道:“我們得把這件事情做對,這一點非常非常重要”。
我對走勢的預測
鑑於目前的情況,我認為要想理解會發生什麼以及如何發生,有三個關鍵點需要關注。首先,在把“聲譽風險”報告為未來的主要障礙方面,Google究竟是在跟誰對抗?其次,用 LM 以及當前的 AI 安全/對齊(AI alignment,指引導人工智慧系統的行為,使其符合設計者的利益和預期目標)技術有沒有“做對”的可能性?第三,即使可以做到,並且公司認為應該這麼做,有沒有可能從中衍生出可行的商業模式?
Google真正的敵人
我在查看皮查伊和 Dean 關於 ChatGPT 威脅的觀點時,注意到了一些怪異之處:他們似乎在暗示Google正在與 OpenAI 競爭。OpenAI 的技術確實被Google高管認定為“紅色警戒”,但我認為 OpenAI 不會對Google構成威脅——這種思考方式是不對的。
一方面,在技術研究與人工智慧專業知識方面,OpenAI 是沒法跟Google競爭的。哪怕只看絕對數字,Google的預算和人才也遠遠勝於 OpenAI。正如 Emad Mostaque 所認為的那樣:
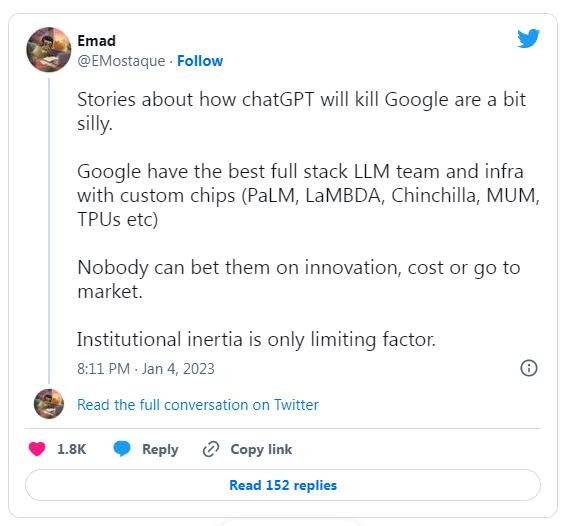
認為ChatGPT會幹掉Google的文章很可笑。Google擁有最好的全端LLM團隊與基礎設施,還有自己的定製晶片。無論是創新、成本還是GTM都沒人能跟Google比。機制惰性只是限制因素。
但另一方面, OpenAI 並不想跟Google競爭。
OpenAI 的聲譽風險要遠低於Google,因為它是一家歷史相當短暫的小型公司,充其量只為幾百萬使用者提供服務,而據估計,全球有超過 40 億人在使用Google搜尋,後者佔據了驚人的 84% 的市場份額。
不過,OpenAI 據稱的使命是開發出有益的通用人工智慧(AGI)。這個目標無疑要崇高得多,所以為什麼要冒險到一個與其主要目標完全不重疊的領域,並跟一家更大的公司硬碰硬呢?
即便 OpenAI 最終的目的是為了經濟利潤(不可否認,推翻Google會催生一個成功得不得了的賺錢機器),該公司也有不會與其長期目標相衝突的更好選擇,比如建立付費訂閱或付費使用模式,就像他們現在所做的那樣(像GPT-3 和 DALL-E)。
不管是從影響力、規模、預算還是最重要的目標來看,Google真正的競爭對手都是微軟。但是,如果你是這麼看的話,Google被迫面對更高聲譽風險的觀點就不攻自破。因為微軟的使用者規模與Google相當,微軟也必須維護其精心打造的聲譽——正如 2016 年它決定關閉帶有種族主義偏見的聊天機器人 Tay 時所表明的那樣。
“聲譽風險”論的支援證據之一是,微軟在搜尋市場的份額要比Google小得多,二者根本無法相提並論。但是,如果微軟將 LM 與搜尋相結合的嘗試成功的話,他們的使用者數量就會增加,因此聲譽風險也會相應增加。
微軟有待回答的問題是,他們肯不肯做出將 ChatGPT 整合到 Bing 的決定——願不願意為了有機會推翻Google,推出能力更強的新服務去吸引使用者,而冒聲譽受損的風險?
Google打算如何應對?
“把事情做對”。這個目標聽起來不錯,但卻不切實際
Jeff Dean 的解釋是,Google正在等待“把事情做對”的時機,這讓我想起了我對某些觀點給出的類似評價。有人認為應該將倫理原則嵌入到人工智慧模型之中,以及認為應該打擊虛假資訊。雖然這些是很重要,但更多隻能是希望,不具備現實可行性。屬於說得好聽,但做起來很難很難的事。
在我看來,按照 Dean 的意思,把 LM 做對的唯一辦法是重新定義、重新設計、徹底再造。如果按照 Gary Marcus 的說法,他們根本就沒有足夠的能力做到真實、可靠與中立,那任何臨時性的護欄都沒法遏制那種邪惡性,因為這種邪惡源自提供給 LM 的資料。
也可能會這樣,一旦有公司嘗試將 SE 與 LM 結合起來,讓前者顯得可靠的所有關鍵特性都會因 LM 缺乏功能設計而中毒。關於這一點,Marcus 在對Perplexity、Neeva 以及 You 的分析中已經展示了大量證據。他的結論暫且擱置爭議,讓大家對未來還抱有希望:
怎麼說呢? Perplexity.ai 以及 you.com 的聊天其實探索了一個很有趣的想法:將典型的搜尋引擎與大型語言模型結合在一起,也許可以加快更新的速度。但是,要想把典型的搜尋與大型語言模型整合好,還有大量工作要做。
另一個問題是當前最先進的 AI 對齊技術是否已經足夠好,或者能否引導 AI 朝著正確的目標前進。Scott Alexander 寫過一篇好文,講的是 ChatGPT 使用的人工反饋的強化學習(RLHF)有何侷限性,但這似乎是公司阻止 LM 行為缺陷的唯一方法了。
對此 Alexander 並沒有遮遮掩掩:“RLHF 效果不佳。”正如我之前說過的那樣,“人很‘容易’就可以突破它的過濾器,而且 AI 很容易被提示注入(prompt injections,類似於 SQL 隱碼攻擊,指惡意使用者哄騙 AI 做偏離原先用意的事情)。” 針對 RLHF 最佳化過的模型也可能會陷入到優先順序衝突的循環之中。 Alexander 說,“懲罰無用的答案會讓 AI 更容易給出錯誤的答案;懲罰錯誤的答案會導致人工智慧更有可能給出令人不快的答案;諸如此類。”想讓 LM 生成同時具備有用、真實和非冒犯性的回應也許是不可能的。
此外,如果用 RLHF 對 LM 進行改進的效果是逐漸逼近的話,就像 Alexander 懷疑的那樣,我們將永遠也沒法“做對”。不過,鑑於這是表現最好的方法,所以公司可能會沒有動力花費時間和資源去研究另一個可能會(也可能不會)像 RLHF 一樣有效的好點子。
如果以上所有事實被證明都正確——也就是 LM 本質上不適合搜尋,而我們可以用上的最好技術也很平庸的話——那麼短期內就不會出現“做對”的時刻,這是 Jeff Dean 的願望,也是Google的需要。
Google將面臨兩難選擇:一方面,他們可以讓微軟去牽這個頭,為了最終重新定義搜尋未來並成為該領域下一個霸主,去承擔“聲譽風險”。另一方面,他們可能會認為“把事情做對”這個目標過於雄心勃勃,選擇採取一種平衡的做法,自己去承擔聲譽風險,一邊推出不成熟的功能(比如“現在已經做得更好”的功能),一邊採取公關舉措(比方說“我們已盡了最大努力”)——從而在人工智慧和搜尋領域都保持著領先地位,並在接下來的幾十年中倖存下來。
如果最後要歸結為Google必須在名聲與生命之間做出選擇的話,我想我們都知道會發生什麼。
LM 驅動的搜尋會影響賺錢嗎?
但接下來還有最後一個挑戰,如果其他一切都朝著有利於Google的方向發展的話,這個攔路虎仍不可避免。對微軟來說也是如此。如果搜尋是靠廣告商業模式盈利的話,那怎麼才能在不需要點選任何內容的情況下靠 LM 驅動的搜尋盈利?
如果是Google來牽這個頭的話,又能否找到一種方法,圍繞 LM 驅動的搜尋建立起自己的護城河,同時圍繞 LM+ 搜尋設計出一個新穎可行的商業模式?二十年前,Google 的 PageRank 演算法與廣告模型是無與倫比的組合。Google能不能重新上演這一壯舉呢?
當然了,如果我們能享受到沒有廣告的網際網路的話,那自然好。不過,替代方案是將搜尋轉變為付費服務。大家願意接受如此反慣性的改變嗎?
我覺得另一種可能性(這可能只是個瘋狂的假設)是微軟可以決定將搜尋商品化,讓它變成一種非營利性的服務(沒有廣告,也沒有任何其他形式的貨幣化),其唯一目標是在幾年之內讓Google從地圖中消失。
但是,還有其他問題可能會阻止微軟做此嘗試。正如 Marcus 在他的文章中解釋的那樣,目前的搜尋比 LM 要便宜得多,而且速度也快得多。這意味著企業很敏感的利潤會減少。微軟在與Google競爭的同時會耗盡自己的資金,這會讓雙方都陷入困境,這似乎是一項非常冒險的商業操作。
不管最終走勢如何,很明顯,二十年來幾乎停滯不前的搜尋領域即將迎來前所未有的拐點。
譯者:boxi。
本文經授權發布,不代表36氪立場。
如若轉載請註明出處。來源出處:36氪
