
 Yahoo奇摩新聞
Yahoo奇摩新聞 只要掃一眼,電腦就能看見所有物件!中研院開源演算法,把李遠哲理念傳到全球
全球掀起AI浪潮,在這波浪潮下,有許多台灣企業長期在專注AI領域開發,並有了令人振奮的成果,為此,《數位時代》與數位發展部合作「2023台灣AI大賞」,評選出對AI產業具有影響力的台灣團隊與專案。以下為獲獎團隊 中研院資科所 YOLO 研究團隊 的故事:
物件偵測(Object Detection)是電腦視覺(Computer Vision)領域裡的重要應用發展方向,是圖像辨識(也稱影像辨識)的重要研究領域之一。長久以來,電腦科學家就一直想要教會電腦如何像人類一樣,能夠掃過一眼就「看見」各種東西。
在現今的AI真正崛起之前,傳統用來偵測物體的電腦視覺技術,多半需要大量仰賴人工的各種方法,對特定的環境進行調整。只要是過去沒有見過的新情況,電腦對物件的辨識度可能就會大幅下降。對於物件較複雜的場景,辨識的效率與精確度也通常結果較差,需要花非常多的時間與運算資源才能運作。
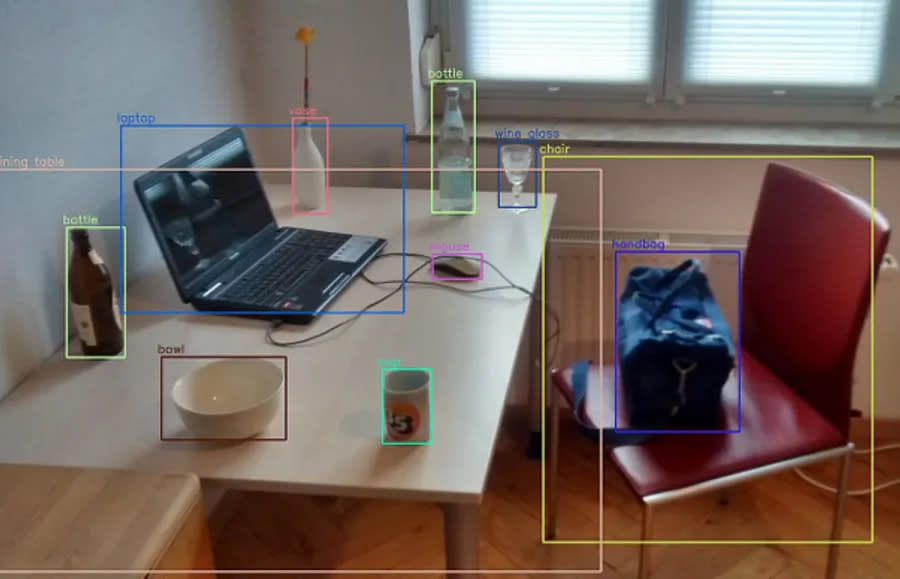
2012年以來,開始有研究團隊導入機器學習來處理物件偵測的問題,引用現今稱為深度學習的方法,讓程式可以自動從大量的數據學習各種物件的特徵,使AI模型具有更好的通用能力以及效率,自此取得了突破性的進展。例如 R-CNN 系列、YOLO、SSD、Google 開發的 EfficientDet 都是相當重要的物件偵測模型。終於讓電腦能夠「看見」各種東西,以進行影像辨識的後續分析和應用。
其中第4版的 YOLO 演算法,正是由中研院資訊科學研究所廖弘源所長、王建堯博士與俄羅斯開發者博科夫斯基(Alexey Bochkovskiy)共同開發的成果,平均正確率(Average Precision, AP)達43.5%,比前一代(YOLOv3)提高10%,如果應用於交通車流分析,正確率更可以達到9成以上。

根據 Google Scholar 的統計,自該論文2020年4月在 Arxiv 發布以來,至截稿為止的 2023 年 6 月初,被引用的次數已經超過了1萬次以上,創下中研院的紀錄。更是繼 Google Brain 團隊在 2017 年發布 Transformer 模型的文章: Attention is all you need、Open AI 團隊在 2020 年發布 GPT-3 模型的文章 Language Models are Few-Shot Learners 以來,影響人工智慧應用領域的重要學術研究論文。
在開源的基礎上開發,再將演算法開源與全人類分享研究成果
與其他的演算法相比,YOLO 最大的優勢就是運算速度,YOLO 只需要掃描圖片一次,就能夠即時進行物件偵測。 王建堯表示,團隊在一開始能夠運用的運算能力很低,因此從開發初期就考量要以較低的硬體需求,做出更好的正確率。也因此 YOLO 成功地降低了使用門檻,讓任何人都能運用此演算法。與 Google 花了其自行開發的 128 部 TPU 進行開發相比,YOLO 的開發團隊僅使用了 8 部 NVIDIA 的 V100 即達到更好的效果。
也由於硬體要求較低,因此在演算法開源之後,就陸續有各種團隊將 YOLO 應用到計算車流量、自動駕駛、工廠品管流程、病理影像分析等無數的產業應用上,影響力既廣且深遠。

「所有關心物件偵測演算法的頂尖人才,從學術與產業應用都在網路上直接討論,讓我做研究一點也不覺得孤單。」王建堯說,能站在開源的環境研究與開發,是可以立足台灣就做到國際級研究的基礎。在研究完成的同時,能將再次演算法開源與全人類共享研究成果,是 YOLOv4 能夠在世界上具有這麼大影響力的重要關鍵。「後續收到許多電子郵件的詢問,有許多國內外產業界的團隊,紛紛打電話、甚至拜訪我們,詢問各種將 Yolo 模型實務應用上的問題,讓我們更確定了開發這個演算框架的影響力。」
王建堯指出,演算法開源後,全世界的開發者都會協助補足研究上還不夠完美的地方,靠世界上許多的開發者一起讓整個技術更加完整。「李遠哲博士曾經說過『 知識應為全人類共有 』,這個觀念讓我深受感動。因此我很支持開源的決定。」廖弘源提到開源對人類的重要。

科學家要用系統化的方法解長遠的問題
如今廖弘源、王建堯與 Alexey Bochkovskiy 在 YOLOv4 之後,繼續推出 Scaled YOLOv4,YOLOR 與最新的 YOLOv7 版本,持續改善模型的架構與訓練過程。「這個過程並不是一蹴可及的。」廖弘源回憶起,當時王建堯接手他的實驗室與義隆電子合作的智慧交通專案時的場景,「最初他每周舉行的內部會議中提出了一個想法,想利用梯度分流來提高模型準確度和運算效率。我認為那是一個很科學的點子,我就鼓勵他這是我5年內聽過最好的演講。」
不過,王建堯第一次嘗試開發出速度快、低功耗的輕量級電腦視覺模型 PRN,速度雖然比 YOLOv3 快兩倍,但準確度卻較差。他隨後又在2019年研發出 CSPNet,終於解決了卷積網路梯度消失的問題,大幅提升演算法的學習效率,在速度不變的前提下,CSPNet 辨識的準確率甚至比 YOLOv3 還要高出 15%,其成果也引起在產業仍持續投入維護 YOLO 專案的研究者 Alexey Bochkovskiy 的興趣,提出合作邀約更新為現今最知名的第四代版本:YOLOv4。

「未來,我們希望能夠讓既有的模型,繼續朝著多模態多任務(Multimodal Multitasks)的方向前進。」王建堯說,讓 YOLO 模型不只輕巧、快速、準確度高,還能運用不同的IoT感測器,收集影像、影片、聲音、溫濕度等不同型態的資料,並面對複雜情境,讓 YOLO 能完成處理更複雜的任務。
責任編輯:林美欣
