
 Yahoo奇摩新聞
Yahoo奇摩新聞 Meta公布AI語音模型支援4000種語言! 以《聖經》為範本打造多國語言資料庫
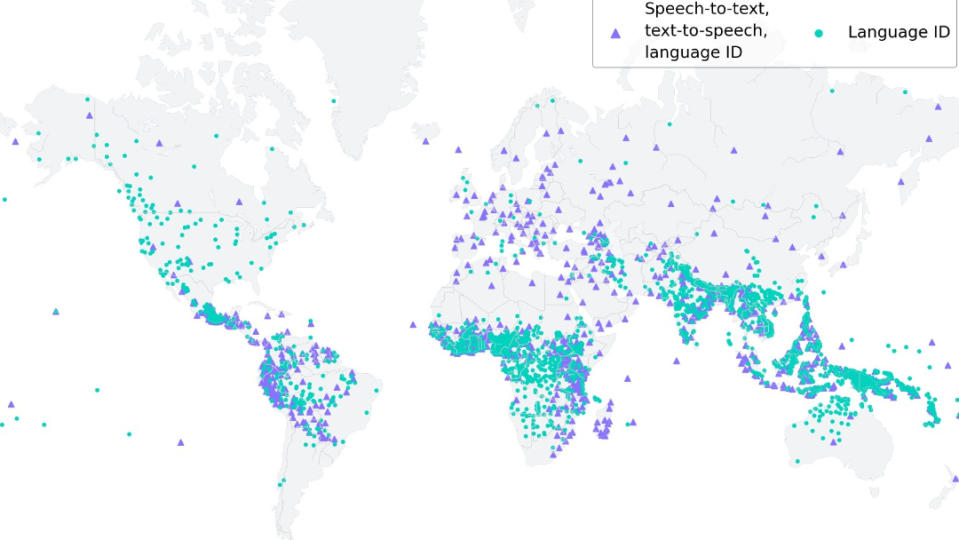
Meta去年曾發表「台翻英」在內的多國AI語音翻譯系統,如今又有新進展!該公司研發完成的MMS大規模多語言語音模型目前已可辨識超過4000種口語表達的語言,且支援語音轉文字的應用範圍已從100種語言增加到1100種,並完成多國語言版《新約聖經》有聲讀物資料庫。Meta表示,此技術還可應用於AR、VR,讓大家在虛擬世界中也能使用自己偏好的語言,而且聽得懂對方在說甚麼。
Meta表示,世界上許多語言正面臨消失的危機,而現有的語言辨識與生成技術上的限制更加快此趨勢;該公司於今(5/23)發表系列大規模多語言語音模型(Massively Multilingual Speech AI;簡稱MMS),希望藉此幫助大家以自己習慣的語言,更輕鬆地獲取資訊及使用電子裝置。新版語音模型已可辨識超過4000種口語表達的語言,辨識量是既有技術的40倍
MMS並支援「文字轉語音」及「語音轉文字」的技術應用,至今已可轉換超過1100種語言,是過去的10倍。Meta並宣布,將開放這項技術的原始碼及模型,讓研究社群能夠以現有的工作成果為基礎繼續開發,一同保存全球的語言,加強人們的溝通,不受距離和語言因素而限制。。
過去最大型的語音資料庫最多僅涵蓋100種語言,因此開發此技術所面臨的第一個挑戰即為「蒐集數千種語言的語音訓練資料」。為了克服這項挑戰,Meta 使用已翻譯成多種語言、譯文已被廣泛閱讀及研究的宗教經典:《聖經》,作為語言的文字訓練資料。
《聖經》譯文有多種語言的公開錄音檔,作為大型多語言語音模型計畫的一部分,Meta創造的資料集,蒐集超過1100種語言的《新約聖經》有聲讀物資料庫,平均為每種語言提供32小時的語音訓練資料,後續又加入其他未標註的基督教有聲讀物後,可用的語言訓練資料已涵蓋超過4000種語言。
Meta表示,雖然資料集收錄的聲音以男性居多,但測試成果顯示,不論是男性或女性的聲音,此語音模型皆能同等準確地辨識。此外,上述的語言訓練資料大多為宗教相關的內容,但Meta分析顯示,這並不會使模型傾向於生成出更多的宗教性質的語言。
