
 Yahoo奇摩新聞
Yahoo奇摩新聞 
谷歌贏兩次?AI作畫大師Parti一出,DALL-E 2.0成「爺爺輩」了
最近,在「AI畫畫」這一塊,大廠們又捲上了新高度!
4月,在GPT-3大模型的加持下,Open AI對畫圖界的扛把子DALL-E進行了2.0版的全面升級。
讓自然語言生成圖像達到了全新的高度。比如下面這幅「孫子玩兒電腦」(非罵街)。

5月,谷歌不甘落後推出AI創作神器Imagen,效果奇佳。
號稱重奪AI畫畫老大哥地位的Imagen,迅速被國外網友玩出了新高度,一波「虎戴VR」熱度直接起飛。

有人驚呼,現在的新模型的保質期只有一個月了麼?
谷歌一看,這是要開卷的節奏,不如我再進一步,再搞個新的AI大畫家吧。
於是,只過了一個月,新一代AI繪畫大師Parti就來了!

Parti,全名叫「Pathways Autoregressive Text-to-Image」,是谷歌大腦老大Jeff Dean提出的多任務AI大模型藍圖Pathway的一部分。
Jeff Dean在社交媒體上第一時間推廣了一波。

同時他也表示,和一個月之前的「老前輩」Imagen相比,這次的Parti使用的是不同的技術路線。
為此,谷歌AI專門寫了一篇博客文章,對比了兩個「AI大畫家」在技術層面上的區別。
雖然Imagen和Parti使用類似技術,不過但具體的策略是不同的——自回歸和擴散。這樣互補的方式使得兩個強大模型的有了更加令人期待的組合!
從Imagen到Parti,谷歌又整了啥新活?
先來回顧一下「老前輩」Imagen,它是一個Diffusion模型,學習將隨機點的圖案轉換為圖像。
這些圖像首先以低分辨率開始,然後通過超分辨率技術,不斷的豐富圖像的信息,進而達到提高圖像分辨率的目的。
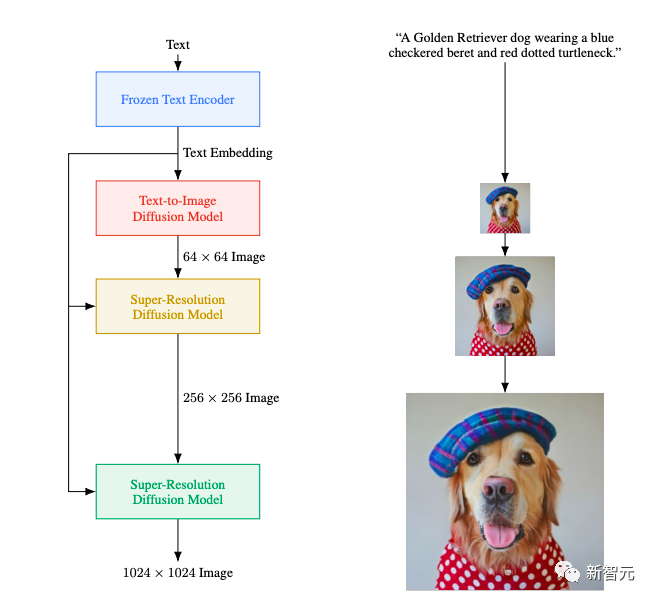
具體點講,就是:
在用戶輸入文本後,如「一隻戴著藍色格子貝雷帽、穿著紅色波點高領毛衣的金毛犬」,Imagen先使用一個凍結(frozen)T5-XXL 編碼器將輸入文本映射到嵌入序列和64×64圖像擴散模型,再將生成的64×64圖像上采樣為256 × 256圖像,最後上采樣為1024 × 1024圖像。
而這次新推出Parti是一個自回歸模型,它的方法首先將一組圖像轉換為一系列代碼條目,類似於拼圖。然後將給定的文本提示轉換為這些代碼條目並「拼成」一個新圖像。
換言之,Parti將「文本到圖像的生成」轉換成一個「序列到序列」的建模問題,類似於機器翻譯——這使得它能夠受益於大型語言模型(如PaLM),這對於處理長而復雜的文本提示和生成高質量的圖像至關重要。
在這種情況下,目標輸出是圖像token的序列,而不是另一種語言的文本token。
Parti通過使用功能強大的圖像標記器「ViT-VQGAN」將圖像編碼為離散token序列,並利用其重建圖像token序列的能力,使其成為高質量、視覺多樣化的圖像。

參數從3.5億到200億:有啥區別?
Parti的模型規模支持擴展,最高可擴展至200億參數。
參數越多,模型規模越大,生成圖像的細節越豐富,錯誤信息也明顯降低。
比如面對同樣的文本輸入:
身穿橙色連帽衫和藍色太陽鏡的袋鼠站在悉尼歌劇院前的草地上,胸前舉著寫著「歡迎朋友」的標語

在3.5億參數下,袋鼠的眼鏡不是藍色,而且PS痕跡明顯,背景只體現出「草地」,悉尼歌劇院基本看不出來。舉的牌子上更不知道是哪國文字。
到了7.5億參數下,眼鏡顏色和背景都和文字准確對上了,但卻多了另一隻帶著藍眼鏡的袋鼠。
擴展到30億參數,之前的袋鼠不見了,但舉的牌子多了一塊,上面的字仍有拼寫錯誤,但大概能看出是「歡迎朋友」了。但背景中的悉尼歌劇院似乎開了「影分身」。
最終在200億參數下,文字中的內容得到准確再現。
換一張圖,也是如此。文本信息細節越少,體現的越明顯。
比如文本是「小提琴的背面」這幾個字:

直到30億參數下,生成的圖像仍然是「小提琴的正面」,直到200億參數下,才生成了正確的圖像。
多面手「藝術家」,風格百搭
除了由模型參數量擴大帶來的細節提升外,畫畫最要緊的是能畫出不同風格,要都是千篇一律,那還叫藝術家嗎?
Parti表示,這挺簡單的。
比如命題作畫:
一隻浣熊穿正裝,頭戴禮帽,拄著枴杖,拿著個垃圾袋。
就能畫出梵高風格的:

埃及法老風格的:

甚至是像素藝術風的:

再比如下面的文字:
「一隻老虎戴著列車長的帽子,手裡拿著一塊滑板,上面有一個陰陽符號。」
也可以畫成油畫風,真真的那種 。

或者版畫風,酷酷的那種。

甚至國畫風,萌萌的那種。

當然,也有翻車的時候。
比如下面這個作品,文字是「一個沒有香蕉的盤子,旁邊有一個沒有橙汁的玻璃杯。」

然而,生成的圖片中盤子裡全是香蕉,玻璃杯裡也幾乎盛滿了橙汁!
就當是藝術家偶爾打了個盹吧!
看起來,以後「斗圖界」說不定可以告別表情包了,想要什麼圖,打字就行了!
早些年要是能有這樣的神器,「美術課恐懼症」的小編可能也會免去不少不堪回首的回憶吧。
參考資料:
https://parti.research.google/
https://blog.google/technology/research/how-ai-creates-photorealistic-images-from-text/
本文來自微信公眾號“新智元”(ID:AI_era),編輯:David 如願 好困,36氪經授權發布。
本文經授權發布,不代表36氪立場。
如若轉載請註明出處。來源出處:36氪
